1
2
3
4
As robots become more prevalent, optimizing their design for better performance and efficiency is becoming increasingly important. However, current robot design practices overlook the impact of perception and design choices on a robot's learning capabilities. To address this gap, we propose a comprehensive methodology that accounts for the interplay between the robot's perception, hardware characteristics, and task requirements. Our approach optimizes the robot's morphology holistically, leading to improved learning and task execution proficiency. To achieve this, we introduce a Morphology-AGnostIc Controller (MAGIC), which helps with the rapid assessment of different robot designs. The MAGIC policy is efficiently trained through a novel PRIvileged Single-stage learning via latent alignMent (PRISM) framework, which also encourages behaviors that are typical of robot onboard observation. Our simulation-based results demonstrate that morphologies optimized holistically improve the robot performance by 15-20% on various manipulation tasks, and require 25x less data to match human-expert made morphology performance. In summary, our work contributes to the growing trend of learning-based approaches in robotics and emphasizes the potential in designing robots that facilitate better learning.
Learning has been one of the most promising tools for operating robots in unstructured environments, enabling them to acquire complex perception and reasoning capabilities. However, the current status quo of designing robots does not account for the impact of learning: rather, many robots are still designed based on human experts' intuition or hand-crafted heuristics. Therefore, such designs can lead to a sub-optimal performance by causing unexpected visual occlusions. This is where the idea of guiding robot design to improve the robot learning capability comes in, inspired by the evolutionary process.
This work particularly aims to discuss the design optimization for vision-based manipulation. In the general context of manipulation, visual sensors provide a rich stream of information that allow robots to perform tasks such as grasping, object manipulation, and assembly. The use of visual sensors in manipulation, however, inevitably poses challenges associated with complete or partial field-of-view occlusion, which can degrade performance due to limited perception (Fig. 1). Whether an occlusion is harmless or fatal often depends on the task at hand and the stage of task execution. Such scenarios motivate us to explore hardware optimization without neglecting the interplay between the robot's morphology, onboard perception abilities, and their interaction in different tasks.
 (hover to play)
(hover to play)
(hover to play)
(hover to play)
Unlike typical two-loop morphology optimization frameworks (Fig. 2 - left), our key idea is to leverage the morphology-agnostic policy $\pi^\triangle$ trained only once. Once the morphology-agnostic controller is learned, we optimize robot design parameters using Vizier optimizer using the controller's performance as a surrogate measure (Fig. 2 - right). Such an approach provides a more accurate evaluation of observability and reachability in terms of "learnability", and it is substantially more feasible than per-design training.
Morphology-Agnostic Controller $\pi^\triangle$ (Fig. 3) is a neural network policy trained to control a wide range of robot morphologies using the onboard camera sensing. The policy $\pi^\triangle$ through learning is primed to disregard occlusions from onboard observation to generate suitable actions. Hence, if the $\pi^\triangle$ is successful, then the information is sufficient, meaning that the morphology does not cause any major occlusions that prevent the task success. The policy $\pi^\triangle$ is used to measure a surrogate performance metric, helping to rapidly assess the quality of different morphologies.
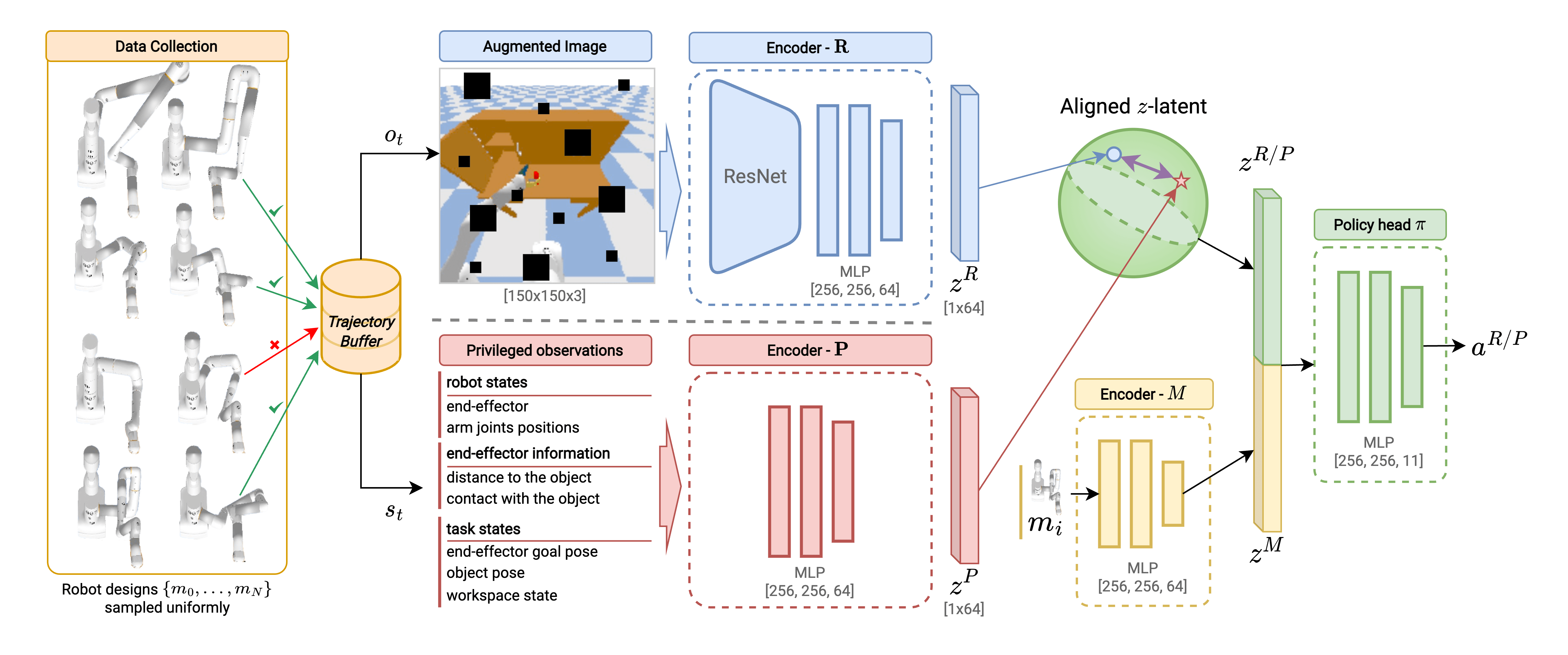
To train MAGIC, we introduce PRIvileged Single-stage learning via latent alignMent (PRISM), which unifies the traditional two-stage approach into single-stage by using a latent space alignment loss during the optimization process. Fig. 4 summarizes the overall architecture of PRISM.
Single-stage unification allows us to discourage the student policy from learning behaviors which incorrectly exploit the information only present in privileged states (Fig. 5 - left) which is important to learn realistic vision-based policies (Fig. 5 - right). To make this approach possible, we use a combination of loss functions to train the policy network. We use Behavioral Cloning for action and explicitly align information in the encoder latent space.
We use reaching and manipulation tasks for training the policy. The reaching task involves moving the end-effector to a specific goal position, while the manipulation task involves picking an object, placing it in a cabinet, and closing the cabinet door (Fig. 7).
The data collection process involves initializing a morphology with uniformly sampled link lengths (Fig. 8) and collecting trajectories using a motion planner (IK with collision avoidance). We use PyBullet simulator to collect the demonstration data. In total, we collect 500k successful trajectories for training the MAGIC policy.
The objective function for the optimization is the success rate of the morphology-agnostic policy $\pi^\triangle$ on the task of reaching and/or manipulation. The success rate of $\pi^\triangle$ serves as a surrogate measure of the robot morphology quality. We use a sampling-based optimization algorithm Vizier, to optimize robot design parameters, to efficiently search for the optimal solution among a large number of possible morphologies (Fig. 9)
A targeted policy $\pi^T$ is a controller designed to control a specific robot, unlike a MAGIC $\pi^\triangle$ policy, which is designed to perform well across multiple robots. We use targeted policy as an ablation to evaluate how much the performance of our proposed MAGIC policy $\pi^\triangle$ is compromised to accommodate for multi-morphology capability. We train the targeted policy $\pi^T$ using PRISM but with a fixed robot design. For a particular robot, we collect $100$k successful targeted demonstrations while keeping morphology $m_i$ intact during the data collection process. We use targeted demonstration to train the targeted policy $\pi^T$ from scratch until convergence.
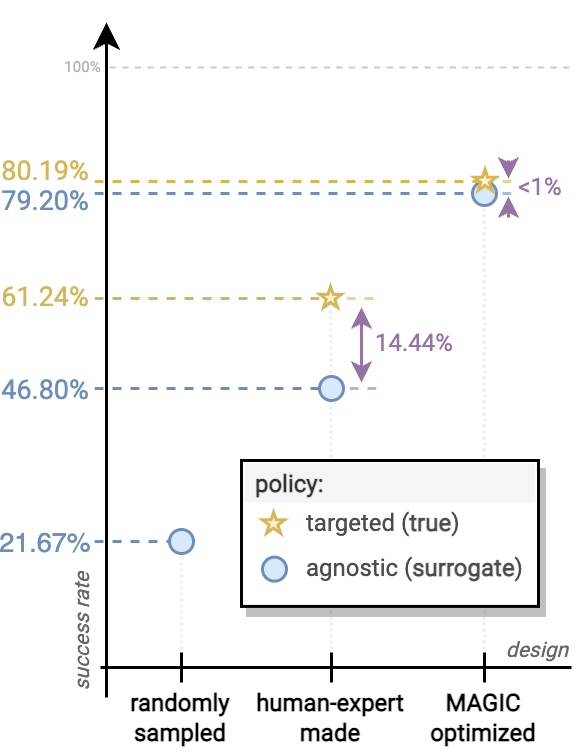
We report the performance of the morphology-agnostic controller $\pi^\triangle$ and targeted controller $\pi^T$ on a human-expert robot design $m^H$ and the best MAGIC-optimized solution candidate $m^\star$ (Fig. 10). We find that the reaching task performance of the $\pi^\triangle$ and $\pi^T$ is nearly identical for $m^H$ (difference: <1%). On the other hand, the performance on $m^\star$ design has a gap of 14.44%. We hypothesize that $m^H$ causes less occlusion and hence is easier to control using $\pi^\triangle$ compared to $m^H$. However, policy $\pi^T$; can learn to exploit the structure of occluding arm to infer the missing information, such as a rough pose of an end-effector, through targeted re-training.
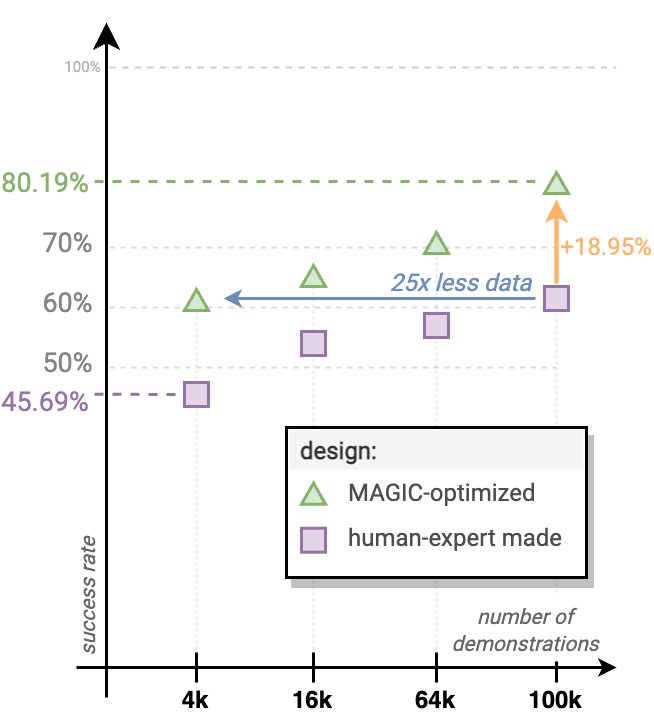
Next, we analyze the difference between MAGIC-optimized $m^\star$ and human-expert $m^H$ designs in terms of
task performance and learning efficiency (Fig. 11).
We highlight the absolute performance improvement of targeted policies when evaluated on $m^\star$ compared
to $m^H$ on the task of reaching.
Specifically, $m^\star$ achieves success rate of 80.19% compared to 61.24% with $m^H$.
The performance gain on $m^\star$ could be attributed to a reduced frequency of sensor occlusions.
We hypothesize that the reduced distortion of onboard information can also result in a higher quality of data
during collection, which naturally leads to improved robot learning capabilities.
To measure the learning efficiency, we compare the success rates of the policies trained with a varying number
of demonstrations.
Fig. 11 shows that $m^\star$ is a better-suited robot for learning compared
to $m^H$, as it requires 25x less data than $m^H$ to reach the same performance when training the
controller from scratch.
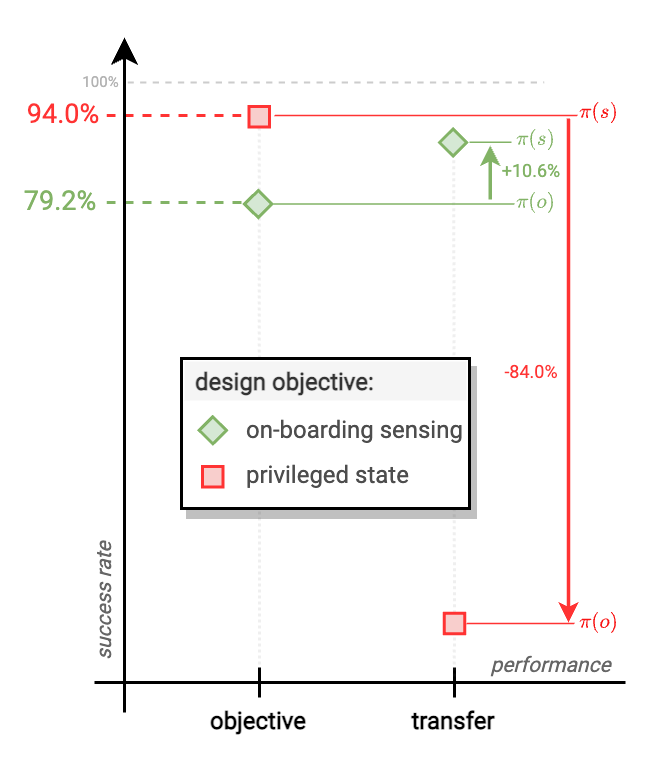
Next, we seek to investigate the significance of onboard sensing during design optimization.
If the robot policy is given access to all of the information present in the environment, a robot may be able
to reach its upper-bound performance, which is mostly constrained by kinematic and dynamic capabilities.
However, it might perform suboptimally when tested with onboard sensing because the morphology can limit its
sensing capabilities via visual occlusions.
We use a privileged controller $\pi_P^\triangle$ during the morphology optimization phase, which acts as an
optimal motion planner with the ground-truth robot and task information.
Once the morphology is found, we evaluate its performance with the policy which relies on onboard information
$\pi_R^\triangle$.
In Fig. 12, we compare the performance of privileged information morphology
and
onboard sensing morphology $m^\star$.
We observe that if we only use the privileged policy during the morphology design, there is a significant
84% drop in performance when the robot is evaluated with onboard sensing. In contrast, $m^\star$ performs
well in both onboard and privileged settings.
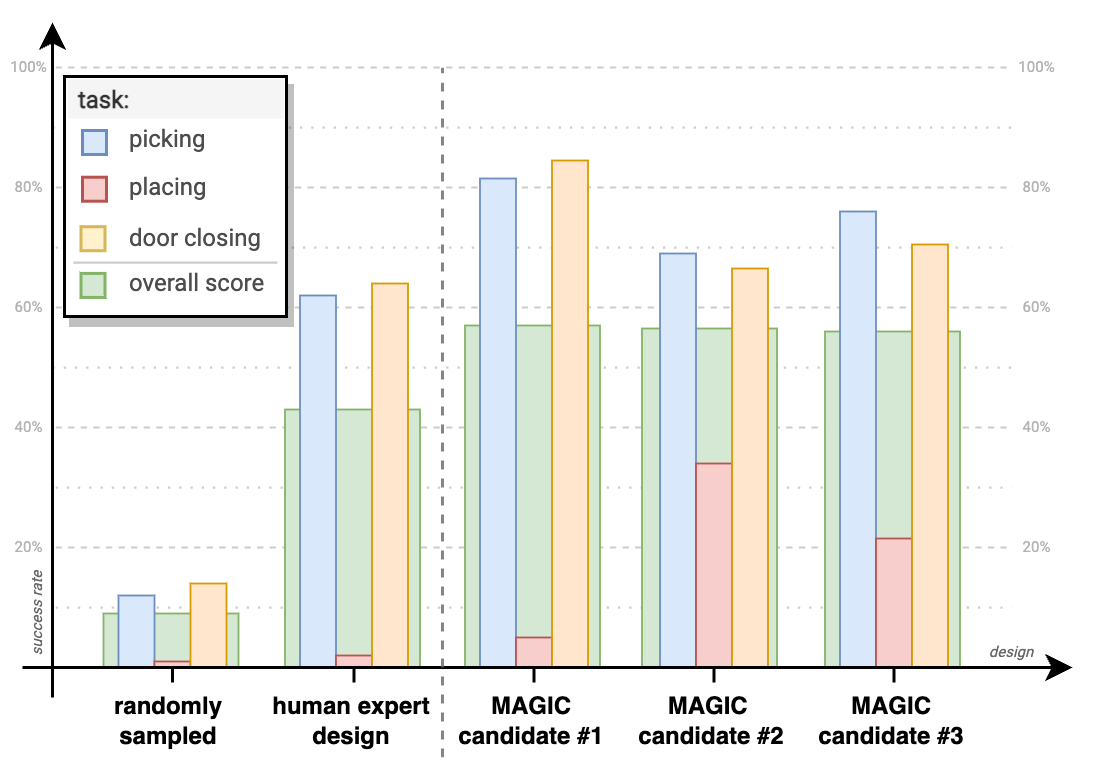
Finally, we investigate the direction of task-based regularization, through the exposure of the robot to a wider set of manipulation tasks. There exists a large number of regularization approaches applied during the optimization to improve the practicality of the design such as energy, or material penalties. However, we intend to avoid an explicit regularization that can directly impact the final morphology. Instead, we seek implicit regularization via learning on multiple tasks. We repeat data collection, training, and optimization procedures with manipulation tasks and report the performance of multiple solution candidates in Fig.13.
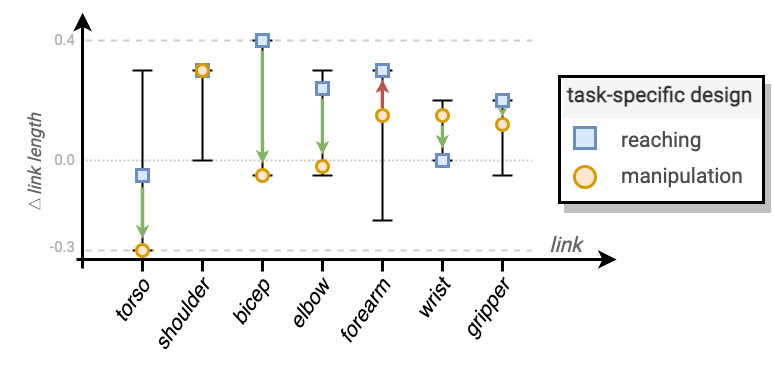
In addition to seeing similar trends in performance improvements of MAGIC-optimized design $m^\star$ in manipulation similar to reaching task, we also observe overall improvements in the robot design solutions. Fig 14. compares two robot morphologies: one optimized for the reaching task, and one that is optimized for the manipulation task. Not surprisingly, the type and complexity of the tasks being considered could significantly impact the optimal morphology design. Hence, including multiple tasks during the optimization process can lead to a more regularized morphology, with shorter and more manageable links that are likely easier to manufacture.
@misc{sorokin2023designing,
title={On Designing a Learning Robot: Improving Morphology for Enhanced Task Performance and Learning},
author={Maks Sorokin and Chuyuan Fu and Jie Tan and C. Karen Liu and Yunfei Bai and Wenlong Lu and Sehoon Ha and Mohi Khansari},
year={2023},
eprint={2303.13390},
archivePrefix={arXiv},
primaryClass={cs.RO}
}